









Large language models (LLMs) are powerful. However, because they operate as “black boxes”, LLMs are difficult to explain and can hallucinate, producing convincing yet inaccurate answers that erode trust. Without an explanation, alignment toward accuracy is a challenging path. Retrieval-augmented generation (RAG) has an answer as it blends traditional or vector search with generative AI, delivering more accurate responses while clarifying the source of truth.
RAG is valuable for businesses, with projections suggesting that 25% of large enterprises will adopt it by 2030. However, RAG has limitations, leading to a growing interest in agentic RAG. They are more intelligent than RAG systems since they use RAG as a tool and reason accordingly if other tools are required.
In this article, we’ll explore the challenges of vanilla RAG, how agentic RAG can address them, and provide a practical implementation using ApertureDB and SmolAgents.
Overview of Agentic RAG
Agentic RAG is an enhanced version of the traditional RAG pipeline, where AI agents are integrated to improve the retrieval and generation process. While vanilla RAG typically involves retrieval with optional reranking and diversification before generation, agentic RAG builds upon this by introducing agents that can::
- Reformulate Queries: Agents can reframe and refine the query based on the context, ensuring more focused retrieval.
- Assess Retrieval Results: Once results are fetched, agents can evaluate their relevance and quality. If needed, they can re-query or adjust the search to improve outcomes.
- Perform Iterative Retrieval: Agents can perform multiple rounds of retrieval, continuously refining the context for more accurate responses. They might rephrase queries, change tools, or use additional sources, ensuring the most relevant information is provided.
- Decision-Making: Agents decide which tools to use (e.g., vector search, web search, APIs) and when to re-query, enhancing the overall effectiveness of the RAG process.
There are many frameworks for creating workflows and working with agents. We will look at SmolAgents, Hugging Face’s lightweight and flexible framework designed for simplicity and first-class support for Code Agents.
Code Agents are a type of agent designed to perform actions by writing and executing code directly rather than returning structured outputs like JSON or text. They integrate with tools and Python functions that include type hints and descriptions and pair them with any language model, including those from Hugging Face, OpenAI, and Anthropic. SmolAgents also integrates with the Hugging Face Hub, enabling users to share and load tools easily.
Why Agentic RAG is Superior
While effective in many scenarios, vanilla RAG has significant limitations that can undermine its reliability. Here are some of the limitations that can be fixed with agentic RAG:
Limitations of Vanilla RAG
- Vanilla RAG relies on a single retrieval step to gather documents. If the retrieved documents are irrelevant or incomplete, the generation step produces flawed responses, as there’s no mechanism to critique or refine the results.
- Semantic similarity in vanilla RAG uses the user query as the sole reference point. This can lead to misaligned results, especially if the query phrasing doesn’t match the structure of the target documents. For instance, questions like "What are the benefits of exercise?" might fail to retrieve relevant documents phrased in statements, downgrading their similarity scores.
- If no relevant documents are retrieved, vanilla RAG might generate highly hallucinated responses instead of exploring alternate approaches like searching the web.
Here’s how to address the above issues:
- Agentic RAG equips an agent to adjust and refine queries dynamically. If the first retrieval attempt fails, the agent critiques the results and formulates a new query to re-retrieve documents. The failure can depend on the number of documents retrieved or the similarity score being less than the threshold or anything dependent on the use-case. Once failure is detected, it can ask the LLM to reformulate the query or ask the user to feed in more context. This iterative process ensures more accurate and complete information is gathered.
- By generating reference sentences closer to the language of the documents (e.g., declarative statements instead of interrogative ones), Agentic RAG improves semantic matching. Techniques like HyDE allow the agent to create hypothetical answers to guide retrieval, while re-retrieval capabilities enable better handling of complex or ambiguous queries.
- When no relevant documents are initially found, Agentic RAG prevents hallucinations by exploring other approaches defined in the tools. For example, it can search the web for relevant information or talk to another database. The possibilities are endless.
Let’s see a use case of the agentic RAG. A customer asks a chatbot, "How do I reset my device?" If the initial search misses relevant instructions, Vanilla RAG might retrieve irrelevant documents or generate an inaccurate response.
In Agentic RAG:
- The agent refines the query to "Steps to reset a device" and extracts the device number.
- It selects the appropriate tool from its list to connect to a database of manuals and retrieve the relevant device number.
- The system fetches the necessary data from the database.
- If the initial results are insufficient, the agent reassesses the query and re-queries using alternative phrasing or generates new snippets to improve accuracy.
Agentic RAG for Research Paper Search with ApertureDB & SmolAgents
Researchers and professionals often feel overwhelmed by the sheer volume of daily academic papers. Traditional keyword-based search engines often return irrelevant results or overlook key studies because they rely on exact matches. What is the main challenge? The vast volume of literature can lead to inefficient reviews and missed opportunities for discovery.
Solution
This guide will walk you through the process of building a solution using Retrieval-Augmented Generation (RAG) with ApertureDB as a vector store and Hugging Face SmolAgents for query refinement and retrieval of research papers. Since research papers are typically in PDF format, we will use the Unstructured library to extract their content. It also supports various other unstructured data formats, offering a range of useful functionalities.
Import and Setups
Before diving into the implementation, let’s prepare the environment.
Setup
Run the following commands to install the necessary dependencies. These include libraries for handling datasets, processing PDFs, generating embeddings, and managing the vector database.
!pip install opendatasets
!pip install 'smolagents[litellm]'
!pip install openai
!pip install smolagents
!pip install unstructured[pdf]
!pip install gradio
!pip install langchain-openai
!pip install --quiet --upgrade aperturedb
!pip install pandas
!pip install langchain-community
!pip install arxiv
We are required to update system packages with sudo apt-get update, install poppler-utils for PDF manipulation, and use pip to add Tesseract bindings for OCR. Finally, install the Tesseract OCR engine (apt install tesseract-ocr) to enable text extraction from images and PDFs.
sudo apt-get update
apt-get install poppler-utils
pip install tesseract
apt install tesseract-ocr
Imports
We’ll use various libraries to handle data fetching, embedding generation, and interaction with ApertureDB. Import these modules in your script:
import os
import json
import arxiv
import requests
import pandas as pd
import opendatasets as od
from langchain_core.documents import Document
from unstructured.partition.auto import partition
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain.chains import (
StuffDocumentsChain, LLMChain
)
from langchain.schema import HumanMessage, AIMessage
from langchain.prompts import PromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate, MessagesPlaceholder
from langchain.callbacks.manager import trace_as_chain_group
import gradio as gr
from smolagents import Tool
from langchain_community.vectorstores import ApertureDB
from smolagents import ToolCallingAgent, LiteLLMModelSetting up the .env File (Optional)
Create a .env file in your project directory to securely store sensitive credentials. This file will store your OpenAI API key.
OPENAI_API_KEY=your_openai_api_keyIn your code, ensure you load these environment variables using the os module:
from dotenv import load_dotenv
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
KAGGLE_TOKEN = os.getenv("KAGGLE_TOKEN")Preparing the Data
We’ll use the ArXiv Papers dataset to simulate a research environment. The dataset contains metadata and content for millions of research papers.
Download the Dataset
To fetch the dataset from Kaggle, run the following:
dataset = 'https://www.kaggle.com/datasets/Cornell-University/arxiv'
od.download(dataset)You’ll need to provide your Kaggle username and API token, which can be generated by creating a Kaggle account and creating a new API token. After providing the necessary information, it will download the dataset.
Extracting and Chunking Data
We’ll process the dataset by extracting paper details from PDFs and splitting the text into smaller chunks.
def fetch_paper_details(arxiv_id):
"""Download and parse a paper from ArXiv."""
paper = next(arxiv.Client().results(arxiv.Search(id_list=[arxiv_id])))
paper.download_pdf(filename=f"{arxiv_id}.pdf")
return partition(f"{arxiv_id}.pdf")
The fetch_paper_details function downloads the PDF and utilizes the partition feature of the unstructured library to identify the file type and extract structured content from the unstructured document.
papers = []
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=5000, # Maximum size of each chunk
chunk_overlap=200, # Overlap between chunks
length_function=len,
is_separator_regex=False,
)
sample = 100 # Limit the number of papers for this demonstration
# Process a subset of the dataset
with open("arxiv/arxiv-metadata-oai-snapshot.json", "r") as file:
for _ in range(sample):
line = file.readline()
data = json.loads(line)
arxiv_id = data.get("id", "")
paper_details = "".join(
text if isinstance((text := element.text), str)
else "".join(str(part) for part in text) if isinstance(text, (list, tuple))
else str(text)
for element in fetch_paper_details(arxiv_id)
)
chunks = text_splitter.create_documents([paper_details])
for idx, chunk in enumerate(chunks):
document_id = f"{arxiv_id}_{idx + 1}"
document = Document(
page_content=chunk.page_content,
id=document_id,
metadata={
'title': data.get("title", ""),
'authors': data.get("authors", ""),
'submitter': data.get("submitter", ""),
'abstract': data.get("abstract", ""),
'paper_content': chunk.page_content
}
)
papers.append(document)We process a subset of an arXiv metadata JSON dataset, extracting and chunking paper content for structured analysis. It uses the fetch_paper_details and splits the text into manageable chunks with overlap using the RecursiveCharacterTextSplitter, and creates Document objects with metadata for each chunk.
Setting Up ApertureDB
ApertureDB is a multimodal database that stores and manages diverse data types, including images, videos, documents, feature vectors (embeddings), and their associated metadata, such as annotations. To get started, sign up here and create an instance.
After creating an instance, wait till the status shows running. Click on connect as shown in the image:
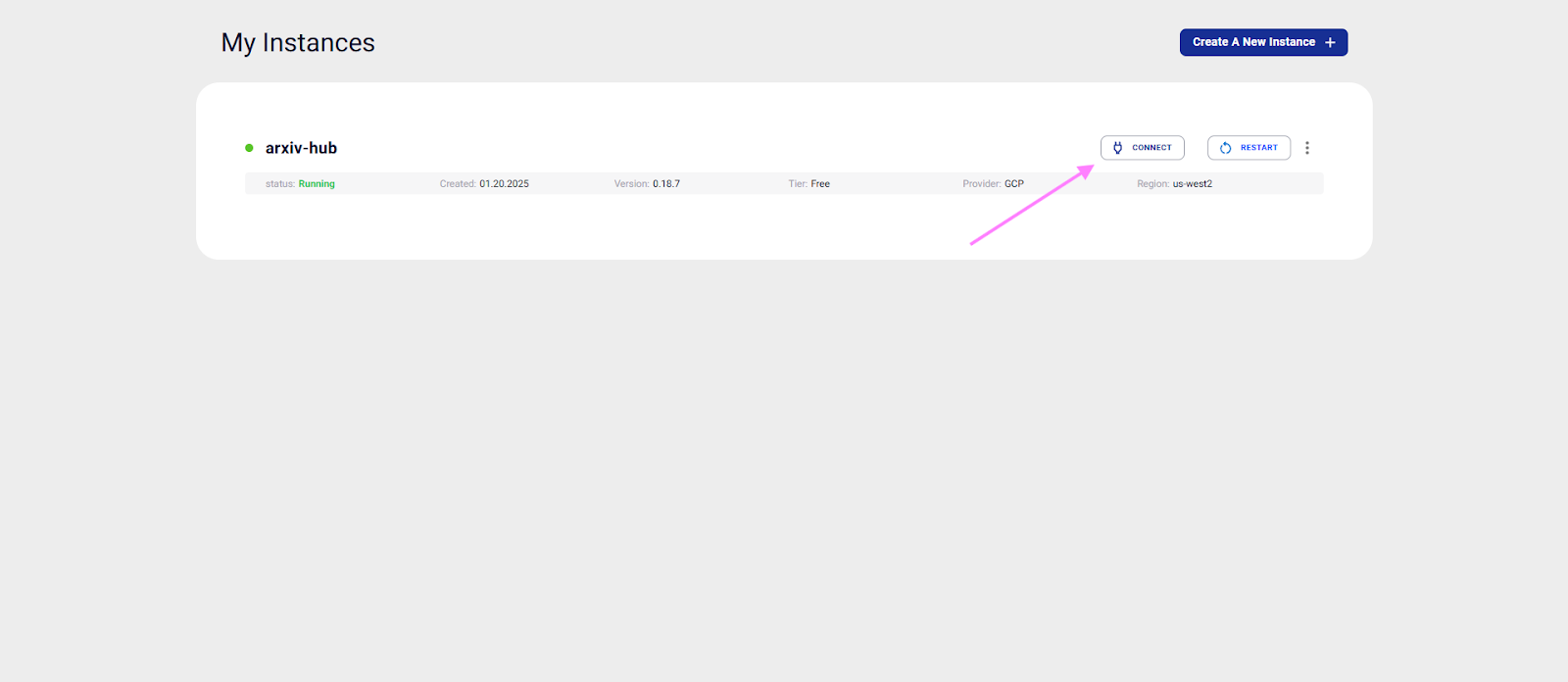
As we are on Colab, copy the connection string for it.
Configuring ApertureDB
We can configure ApertureDB as follows by providing the connection string:
! adb config create --active --from-jsonInserting Embeddings
Once your data is ready, generate embeddings and store them in ApertureDB:
embeddings = OpenAIEmbeddings(api_key=OPENAI_API_KEY)
vector_db = ApertureDB.from_documents(papers, embeddings)It's straightforward: first, load the desired embedding model, and then use LangChain to store the vectors and documents in the ApertureDB vector store.
Building the Agentic Workflow
The workflow involves creating an intelligent agent capable of retrieving semantically relevant documents and dynamically refining queries.
Creating the Retriever Tool
A tool is a class in SmolAgents designed to help the LLM understand its purpose, inputs, and outputs. This makes it accessible within the agent system. Here are the things required to create a tool in smolAgents:
- Key Attributes:
- name: A short identifier for the tool describing what it does (e.g., "document_retriever").
- description: A clear explanation of the tool’s purpose, helping the LLM decide when to use it.
- inputs: A dictionary defining what the tool accepts. For example, a "query" input might have a type (string) and a description explaining its role.
- output_type: The kind of data the tool returns, like "string", tells the LLM what to expect.
- Core Logic (forward): The tool's primary function is implemented in the forward method. This is where the operation happens, such as retrieving documents based on a query.
- Helper Methods (Optional): Supporting methods can be added for reusable functionality, keeping the code modular and clear.
- Tool Initialization: When creating the tool instance, dependencies (like an OpenAI client) are passed into the constructor to ensure it works as intended.
The RetrieverTool class interacts with ApertureDB to retrieve relevant documents based on semantic similarity.
Here's the rephrased version of the class, name, description, and inputs:
class DocumentRetrieverTool(Tool):
name = "document_retriever"
description = "Performs semantic search to fetch documents relevant to a given query."
inputs = {
"query": {
"type": "string",
"description": "The input query, which should be semantically aligned with the content of the desired documents.",
}
}
output_type = "string"
def __init__(self, openai_client, **kwargs):
super().__init__(**kwargs)
self.embedder = openai_client
def retriever(self, query: str, n=5):
retriever = vector_db.as_retriever(search_type="mmr", search_kwargs={"k": n})
results = retriever.invoke(query)
return "\nRetrieved documents:\n" + "".join(
[
f"\n\n===== Document {str(i)} =====\n" + doc.page_content
for i, doc in enumerate(results)
]
)
def forward(self, query: str) -> str:
docs = self.retriever(query)
return docs
document_retriever_tool = DocumentRetrieverTool(openai_client=OpenAI(api_key=OPENAI_API_KEY))The tool above will retrieve the documents from the ApertureDB with a refined query.
Integrating with ApertureDB
Finally, the retriever tool can be connected to an orchestrator model that can have multiple tools in its hand:
model = LiteLLMModel(model_id="gpt-3.5-turbo")
agent = ToolCallingAgent(tools=[document_retriever_tool], model=model)
question = "Why is calculating Higgs Boson decay important?"
agent_output = agent.run(question)By following this guide, you’ve built a RAG system capable of handling academic papers effectively.
Why Vectorstore is an Important Piece in the RAG Puzzle: Features of ApertureDB
The quality of generation hinges on the retriever’s ability to pull in the most relevant insights from the vector database. That’s why vector stores play an important role in performant RAG applications. This makes it a must to choose the right vector database. Here are the following considerations:
- Scalability: How much domain-specific data will your database need to manage? As your data grows, ensure the database can scale efficiently, supporting potentially billions of embeddings.
- Dimensionality of Embeddings: Different models produce embeddings with varying dimensions. Higher dimensions can capture more context but may lead to slower queries and diminishing returns. Consider a database that can handle all.
- Search Accuracy and Indexing: While ANN improves speed and memory usage, it trades off some accuracy, which may or may not suit your application. Your vector database must support what you require.
ApertureDB provides the following in addition to the above:
- Multimodal Database: Supports various data types, including images, videos, and text, enabling seamless integration of multiple data modalities in RAG systems. In the 2nd part, we will enhance the functionality of the current agent and analyze the images within the arXiv paper to gather additional context.
- Graph Database for Metadata: Facilitates the creation of knowledge graphs by linking multimodal metadata, enriching the context for data retrieval and relationships in RAG systems.
- On-the-Fly Image and Video Modification: Allows dynamic adjustments to images and videos, minimizing data duplication and optimizing resource use in visual RAG workflows.
- Integrations: It integrates with most AI/ML frameworks, like HuggingFace, Langchain, etc., to make development easier and more modular.
Recap
While traditional RAG bridges the gap by empowering LLMs with private knowledge through vector databases, the rising demand for faster, more adaptive AI calls for a shift to next-gen solutions like agentic RAG. They enable multi-step retrieval by refining and adjusting the query depending on the results. In this article, we’ve built an Agentic RAG application to search and ask questions about research papers using ApertureDB and Smolagents.
Feel free to explore and adapt the code to create your version of this use case. You can start experimenting with ApertureDB today, sign up for a free instance, and see the power of agentic RAG firsthand.




.png)















.jpeg)







.png)






